Bayesian model fitting and prior selection¶
The new psignifit version heavily relies on Bayesian methods. So far, our simulations with psignifit seem to indicate that Bayesian inference for psychometric functions (based on Markov Chain Monte Carlo) is superior to maximum likelihood inference with a sampling distribution that is approximated using the bootstrap technique. Here, we present a very general introduction to Bayesian analysis that is specially tailored towards psychometric functions. More elaborate introductions to the topic can be found in most modern textbooks about statistics.
The idea of Bayesian inference¶
The basic idea of Bayesian inference is to treat both, parameters as well as data, as probabilistic. That means,
that a “model” in Bayesian terms is an explicit formulation of the joint distribution of parameters 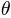 and data
and data 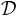
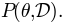
Using the definition of conditioned probability, we can decompose this joint distribution in two ways:

Typically, a model gives us the probability to observe certain data given a set of parameters, that is  .
However, we are usually interested in the opposite: the probability the a given data set was generated by a certain
parameter set, that is
.
However, we are usually interested in the opposite: the probability the a given data set was generated by a certain
parameter set, that is 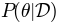 . To get this we can divide both sides of the above equation by
. To get this we can divide both sides of the above equation by 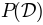 and get the famous Bayes Formula:
and get the famous Bayes Formula:

Once, we have observed a data set, will not change anymore and will be proportional to
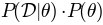 . There is still something tricky about this formula: Getting the probability of
the parameters given the data requires prior knowledge about the parameter that is expressed in terms of
. There is still something tricky about this formula: Getting the probability of
the parameters given the data requires prior knowledge about the parameter that is expressed in terms of 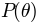 .
That is why typically is called the “prior” distribution.
.
That is why typically is called the “prior” distribution. 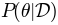 is often called the
posterior distribution, because it is the distribution of parameters after taking into accout the information
contained in the data.
is often called the
posterior distribution, because it is the distribution of parameters after taking into accout the information
contained in the data.
In this section, we will mainly explain how to specify the prior probability
distribution in psignifit. The sections Specifying the experimental design
and Specifying the shape of the psychometric function explain in considerable
detail how the term is specified in psignifit.
Specification of prior distributions¶
Psignifit accepts a list of prior specifications. This list must include one prior specification for each parameter in the model (that means for three parameters in 2AFC, 3AFC, 4AFC, ... and for four parameters in 1AFC/yes-no tasks). Each prior specification is given by a string of the form:
"nameofthedistribution(parameter1,parameter2)"
Thus, a string like “Gauss(0,40)” specifies a normal distribution with mean 0 and standard deviation 40. So a valid form of prior specification for a 2AFC task might be:
prior = ("Gauss(0,100)","Gauss(0,100)","Uniform(0,1)")
Note, that the length of the prior list is crucial. If you don’t specify priors for all parameters, you will get an error message [1].
Prior distributions for lapse rate and guessing rate¶
In the models about psychometric data there were two parameters that can directly be interpreted as probabilities for certain events to occur.
- The lapse rate
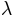 can be interpreted as the probability that an observer misses the stimulus and thus gives a response
based only on guessing
can be interpreted as the probability that an observer misses the stimulus and thus gives a response
based only on guessing - The guessing rate
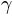 can be interpreted as the probability that an observer gets the stimulus right without having seen it.
can be interpreted as the probability that an observer gets the stimulus right without having seen it.
In certain experimental settings (in particular non AFC settings) the interpretation of these two parameters might change slightly but in any case, they will be probabilities. That means, that these parameters should always be within the unit interval — there are neither negative probabilities nor probabilities greater than one. A simple but also trivial prior for such probabilities would be the Uniform distribution:
"Uniform(0,1)"
This specifies exactly that the parameter can only take values between 0 and 1 and that all values between 0 and 1 are equally plausible.
One might expect that after this, we don’t have to care about these priors anymore. In a way that is right, in a way it is not. We know quite a bit about lapse and guessing rate.
- If lapse rate and guessing rate sum to 1, there is no psychometric function anymore. The data are entirely flat in this case.
- In many cases, we can also easily give an upper bound for the guessing rate. Take for instance a yes-no task in which we want to fit the probability of a correct response. In that case, we can be pretty sure that the guessing rate is somewhere around 0.5. An other example might be that you measured data symmetrically. You might have presented a mark at different horizontal positions and asked for the position of this mark relative to something else (the center of some geometrical figure, the center of the screen, some explicit landmark, an illusory contour, ...). In this case, you can be pretty sure, that the probability that the mark is reported on the right side will be close to zero for points that were presented far to the left. So you could restrict the guessing rate (i.e. the gamma parameter of the model) to be close to zero.
Thus, although a Uniform prior on the unit interval results expresses the most important restriction that keeps the lapse and guessing rates in a range that is at least not impossible, there are other constraints that are relevant.
A first idea is to reduce the interval on which the Uniform distribution is defined. For example for humans, we can usually be quite sure that they don’t lapse in more than 10% of the trials. That can be expressed as:
"Uniform(0,0.1)"
This assigns equal prior probability [2] to any lapse rate between 0 and 10% but assigns a prior probability of 0 to any other value. Although we might feel that this is a good working solution, the translation of it seems odd: It is perfectly fine to find a lapse rate of 9.9% but a lapse rate of 10.1% is entirely implausible and we reject any solution that leads to such a lapse rate.
Another typical prior distribution for parameters that might take values on the unit interval is therefore often the Beta-distribution.
The Beta distribution has two parameters 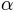 and
and  . We can think of the Beta-distribution in the following way: Imagine performing
a random experiment with two possible outcomes (throwing a coin and looking at heads and tails, throwing a dice and looking at odd and even
numbers, ...). Imagine, we repeated this experiment a couple of times and we observed
. We can think of the Beta-distribution in the following way: Imagine performing
a random experiment with two possible outcomes (throwing a coin and looking at heads and tails, throwing a dice and looking at odd and even
numbers, ...). Imagine, we repeated this experiment a couple of times and we observed 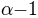 successes and
successes and 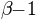 misses. In this
case, the
misses. In this
case, the 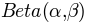 distribution expresses your knowledge about the probability of a success. Thus, we can easily use the
Beta-distribution to express prior believes about lapse rate or guessing rate.
distribution expresses your knowledge about the probability of a success. Thus, we can easily use the
Beta-distribution to express prior believes about lapse rate or guessing rate.
Above, we discussed an experiment in which we consider values of the guessing rate around 0.5 more plausible than others. We could express that using a Beta prior in the following way:
"Beta(5,5)"
You can take a look at this prior by typing the following commands:
from scipy import stats
from pylab import plot, show, mgrid
x = mgrid[0:1:100j]
plot ( x, stats.beta.pdf(x,5,5) )
In some cases, you will have to add an additional line with the show() command.
Also the case, in which we expect only a limited range of a parameter may be expressed by a beta prior. Imagine, we want restrict the the lapse rate to a range that is roughly between 0 and 10%. In that case, we could also use the beta prior:
"Beta(2,20)"
That would correspond roughly to having knowledge from 20 trials on which we know for sure that the observer lapsed only once. This prior gives special emphasis to lapse rates close to 5% but also allows for any other value in the unit interval.
- More generally, you could describe this as follows:
- Beta (a,b)
- lapses = a - 1
- non-lapses = b-(a-1)
- If you are unsure about which distribution would be appropriate for the lapse rate in your data, the following numbers are a good starting point:
- For human participants who show a low lapse rate a Beta(2,20) is a good approximation of the lapse rate.
- For human participants who show a high lapse rate or for a lot of animal experiments a Beta(1.5,12) is a good starting point for your lapse rate.
It is also possible to set the prior 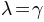 which means that the upper asymptote of the psychometric function is as far from 1
as the lower asymptote is from 0. However, this prior is not yet available from the Python interface.
which means that the upper asymptote of the psychometric function is as far from 1
as the lower asymptote is from 0. However, this prior is not yet available from the Python interface.
Prior distributions for parameters of the psychometric function¶
Selecting priors for the psychometric function depends on the exact parameterization of the psychometric function. We will
explain the reasoning for a logistic-sigmoid and an mw01-core. In this parameterization, the psychometric function depends on the two
parameters 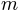 and
and 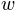 . is the midpoint of the psychometric function. It is what we are often interested in when we talk about
a “threshold”. on the other hand gives the width of the interval on which the psychometric function rises. These two parameters don’t have
natural constraints. The psychometric function is defined for any choice of and . One might therefore be tempted to omit any
priors on these two parameters. This can be done by taking a parameter list like:
. is the midpoint of the psychometric function. It is what we are often interested in when we talk about
a “threshold”. on the other hand gives the width of the interval on which the psychometric function rises. These two parameters don’t have
natural constraints. The psychometric function is defined for any choice of and . One might therefore be tempted to omit any
priors on these two parameters. This can be done by taking a parameter list like:
("improper","improper","Beta(2,20)")
That puts improper priors on the first two parameters ( and ) and a Beta(2,20) prior on the lapse rate as explained above.
Unfortunately, the improper priors are not real probability distributions: They assign a probability of one to any choice of and .
Furthermore, we typically have prior beliefs about these parameters:
- In virtually all cases, we know in advance whether the psychometric function will be increasing or decreasing. For example in contrast detection experiments, we know that for higher contrasts, it becomes more likely that the observer’s report is correct. If in contrast, we derive a psychometric function for detections in degraded images, we know in advance, that the probability of a correct response will decrease as the image is more degraded.
- In some cases, we also know that the threshold can only be within a certain range. For example, contrasts can usually not become negative — thus contrast thresholds can’t be negative either. In any case, we can most often restrict the threshold to a fairly large range of “typical values” in our experiment.
Both these types of prior knowledge can be expressed in psignifit. We start with the first case. A typical prior for the width is the Gamma-distribution. The Gamma-distribution is only defined for values greater than zero. Thus, a Gamma-prior on the width of the psychometric function implies that the psychometric function is assumed to be increasing. The Gamma-distribution has two parameters, a shape parameter and a scale parameter. The shape parameter governs how the overall shape of the Gamma-density is. For shape<1, the Gamma-density approaches infinity at zero. For shape>1, the Gamma-density goes to zero at zero. For higher values, the Gamma-density becomes more and more a bell shaped curve. At shape=2 or shape=3 this curve is heavily skewed and gets smaller as the shape parameter increases. The scale parameter is then only used to scale the the distribution up or down. For example:
"Gamma(2,2)"
Is a skewed bell curve that has been scaled up by a factor of two. A relatively broad prior (i.e. with few prior assumptions) would be a Gamma-prior (allowing only positive values of the parameter) that goes to zero at zero (i.e. shape greater than 1) and is very broad otherwise (i.e. scaled up by a relatively large factor). In a number of simulations about coverage, we used a prior of the form:
"Gamma(1.01,2000)"
This is essentially flat on the interval from 0 to 100 except that it rapidly drops to zero at zero. To plot Gamma priors you can again use scipy:
from scipy import stats
from pylab import plot, show, mgrid
x = mgrid[0:100:1000j]
plot ( x, stats.gamma.pdf ( x, 1.01, scale=2000 ) )
Because of the great flexibility of the Gamma-distribution, psignifit also defines an nGamma prior that expresses the assumption that not the parameter itself follows a Gamma-distribution but that the negative of the parameter follows a Gamma distribution. Thus, assuming a prior for w that has the form:
"nGamma(1.01,2000)"
Is equivalent to the above prior except that it assumes that is negative, i.e. the psychometric function is decreasing.
If we know in advance, that the m parameter will only be negative or positive, it might be sensible to use a Gamma prior for m, too. However, in many cases this is not entirely clear in advance. As an alternative, a Gaussian prior can be used. The Gaussian (or normal) distribution has a symmetric bell shaped density. We can easily shift the position of the bell along the x-axis or changing the width of the bell. This can be combined to select certain ranges of parameters. For example, if we know that the absolute value of m is unlikeli to be greater than 100, we might select a Gaussian prior of the form:
"Gauss(0,100)"
This expresses a prior distribution of m with mean 0 and standard deviation 100, which is close to flat for virtually all practical purposes.
Thus, we can summarize that for most situations only very moderate preassumptions are needed to justify the following priors:
("Gauss(0,100)","Gamma(1.01,2000)","Beta(2,20)")
Or alternatively for decreasing psychometric functions:
("Gauss(0,100)","nGamma(1.01,2000)","Beta(2,20)")
Although these priors seem natural at first sight, it is often a good idea to think a minute about the proper choice of a prior distribution.
For example, uniform priors might also be interesting for and , and Michelson contrast is restricted to have values in the unit interval,
so a Beta prior might also be justified for contrast thresholds.
| [1] | In some cases, you might still want to use Bayesian inference techniques but without a ‘real’ prior for a certain parameter. To specify such an ‘improper’ prior, you could use the empty string “” or explicitely demand “improper”. Such a prior will assign a prior probability of 1 to any value of the respective parameter and is thus no proper probability distribution. |
| [2] | Usually you can translate ‘prior probability’ to ‘plausibility’ |
![]()
Table Of Contents
Previous topic
Specifying the shape of the psychometric function